99 Bottles of OOP
JavaScript Version
2nd Edition Sample
Front Matter, Chapter 1, and
bits of Chapters 2, 8 and 9
Sample from Version 2.2.0 2024-10-18

Read the description.
99 Bottles of OOP
- Colophon
- Your Rights As A Reader
- Dedication
- Preface
- Introduction
- 1. Rediscovering Simplicity
- 2. Test Driving Shameless Green
- 2.1. Understanding Testing
- 2.2. Writing the First Test
- 2.3. Removing Duplication
- 2.4. Tolerating Duplication
- 2.5. Hewing to the Plan
- 2.6. Exposing Responsibilities
- 2.7. Choosing Names
- 2.8. Revealing Intentions
- 2.9. Writing Cost-Effective Tests
- 2.10. Avoiding the Echo-Chamber
- 2.11. Considering Options
- 2.12. Summary
- 3. Unearthing Concepts
- 3.1. Listening to Change
- 3.2. Starting With the Open/Closed Principle
- 3.3. Recognizing Code Smells
- 3.4. Identifying the Best Point of Attack
- 3.5. Refactoring Systematically
- 3.6. Following the Flocking Rules
- 3.7. Converging on Abstractions
- 3.7.1. Focusing on Difference
- 3.7.2. Simplifying Hard Problems
- 3.7.3. Naming Concepts
- 3.7.4. Making Methodical Transformations
- 3.7.5. Refactoring Gradually
- 3.8. Summary
- 4. Practicing Horizontal Refactoring
- 4.1. Replacing Difference With Sameness
- 4.2. Equivocating About Names
- 4.3. Deriving Names From Responsibilities
- 4.4. Choosing Meaningful Defaults
- 4.5. Seeking Stable Landing Points
- 4.6. Obeying the Liskov Substitution Principle
- 4.7. Taking Bigger Steps
- 4.8. Discovering Deeper Abstractions
- 4.9. Depending on Abstractions
- 4.10. Summary
- 5. Separating Responsibilities
- 5.1. Selecting the Target Code Smell
- 5.1.1. Identifying Patterns in Code
- 5.1.2. Spotting Common Qualities
- 5.1.3. Enumerating Flocked Method Commonalities
- 5.1.4. Insisting Upon Messages
- 5.2. Extracting Classes
- 5.2.1. Modeling Abstractions
- 5.2.2. Naming Classes
- 5.2.3. Extracting BottleNumber
- 5.2.4. Removing Arguments
- Step 1: Refer to the property instead of the argument in the method body
- Step 2: Make sure the method can be called with or without an argument.
- Step 3: Stop passing the argument one sender at a time
- Step 4: Ensure that all senders have been updated
- Step 5: Clean up
- Recap
- 5.2.5. Trusting the Process
- 5.3. Appreciating Immutability
- 5.4. Assuming Fast Enough
- 5.5. Creating BottleNumbers
- 5.6. Recognizing Liskov Violations
- 5.7. Summary
- 5.1. Selecting the Target Code Smell
- 6. Achieving Openness
- 6.1. Consolidating Data Clumps
- 6.2. Making Sense of Conditionals
- 6.3. Replacing Conditionals with Polymorphism
- 6.3.1. Dismembering Conditionals
- 6.3.2. Manufacturing Objects
- 6.3.3. Prevailing with Polymorphism
- 6.4. Transitioning Between Types
- 6.5. Making the Easy Change
- 6.6. Defending the Domain
- 6.7. Summary
- 7. Manufacturing Intelligence
- 7.1. Contrasting the Concrete Factory with Shameless Green
- 7.2. Fathoming Factories
- 7.3. Opening the Factory
- 7.4. Supporting Arbitrary Class Names
- 7.5. Dispersing The Choosing Logic
- 7.6. Self-registering Candidates
- 7.7. Summary
- 8. Developing a Programming Aesthetic
- 8.1. Appreciating the Mechanical Process
- 8.2. Clarifying Responsibilities with Pseudocode
- 8.3. Extracting the Verse
- 8.4. Coding by Wishful Thinking
- 8.5. Inverting Dependencies
- 8.5.1. Injecting Dependencies
- 8.5.2. Isolating Variants
- 8.5.3. Grappling with Inversion
- 8.6. Obeying the Law of Demeter
- 8.6.1. Understanding the Law
- 8.6.2. Curing Demeter Violations
- 8.7. Identifying What The Verse Method Wants
- 8.8. Pushing Object Creation to the Edge
- 8.9. Summary
- 9. Reaping the Benefits of Design
- 9.1. Choosing Which Units to Test
- 9.1.1. Contrasting Unit and Integration Tests
- 9.1.2. Foregoing Tests
- 9.2. Reorganizing Tests
- 9.2.1. Gathering BottleVerse Tests
- 9.2.2. Revealing Intent
- 9.3. Seeking Context Independence
- 9.3.1. Examining Bottles' Responsibilities
- 9.3.2. Purifying Tests With Fakes
- 9.3.3. Purging Redundant Tests
- 9.3.4. Profiting from Loose Coupling
- 9.4. Communicating With the Future
- 9.4.1. Enriching Code with Signals
- 9.4.2. Verifying Roles
- 9.4.3. Obliterating Obsolete Context
- 9.5. Summary
- 9.1. Choosing Which Units to Test
- Afterword
- Appendix A: Initial Exercise
- Getting the exercise
- Doing the exercise
- Test Suite
- References
- Acknowledgements
Colophon
Version: 2.2
Version Date: 24-10-18
Published By: Potato Canyon Software, LLC
2nd Edition
Copyright: 2024
Cover Design and Art by Lindsey Morris.
Edited by Julia Trimmer.
Created using Asciidoctor.
JavaScript logo: License, MIT
Your Rights As A Reader
Thank you for buying 99 Bottles of OOP. As the authors of a self-published book, we very much appreciate your purchase.
This book is chock-full of lessons, and readers often write asking if they can share them with others. We commend your desire to pass on what you’ve learned, and ask only that while doing so you respect our rights as authors. This means that while we encourage you to spread the underlying ideas of the book, we restrict your use of its actual content (the specific examples, explanations, and descriptions).
Our bargain with you is as follows:
-
Your purchase entitles you to a single, non-transferable license for your personal use of the ebook related files. You may read and download the ebook you purchased to your personal devices only.
You may not:
-
Sell the book
-
Give it away
-
Distribute it in any way
-
Print it (except for your personal use)
-
-
You may use 99 Bottles of OOP as curriculum in a public education setting (university, code school, secondary school) as long as every student buys or is provided with a legal copy of the book.
Volume discounts are available, and there’s a free-book-for-a-postcard program. Contact human@99bottlesbook.com for information about bulk purchases.
-
You may share one small section (a chapter or less) at a free, public meet-up as long as the material is properly attributed.
-
You may not teach a course based on the entire book, even if this course is free and open to the public.
-
You may not use any part of 99 Bottles of OOP in any endeavor in which you charge for your services.
Dedication
Sandi
To Amy, for everything she is and does, and to Jasper, who taught me that nothing trumps a good walk.
Katrina
To Sander, whose persistence is out of this world.
TJ
To those who have encouraged me, especially my parents and teachers. And to Graylyn, who I try to encourage most.
Preface
It turns out that everything you need to know about Object-Oriented Design (OOD) can be learned from the "99 Bottles of Beer" song.
Well, perhaps not everything, but quite certainly a great many things.
The song is simultaneously easy to understand and full of hidden complexity, which makes it the perfect skeleton upon which to hang lessons in OOD. The lessons embedded within the song are so useful, and so broad, that over the last three years it has become a core part of the curriculum of Sandi Metz’s Practical Object-Oriented Design course.
The thoughts in this book reflect countless hours of discussion and collaboration between Sandi, Katrina Owen, and TJ Stankus. These ideas have been battle-tested by hundreds of students, and refined by a series of deeply thoughtful co-instructors, beginning with Katrina. While none of the authors have the hubris to claim perfect understanding, all have learned a great deal about Object-Oriented Design from teaching this song, and feel compelled to write it all down.
Therefore, this book, now in its second edition. We hope that you find it both useful and enjoyable.
What This Book Is About
This book is about writing cost-effective, maintainable, and pleasing code.
Chapter 1 explores how to decide if code is "good enough." This chapter uses metrics to compare several possible solutions to the 99 Bottles problem. It introduces a type of solution known as Shameless Green, and argues that although Shameless Green is neither clever nor changeable, it is the best initial solution to many problems.
Chapter 2 is a primer for Test-Driven Development (TDD), which is used to find Shameless Green. This chapter is concerned with deciding what to test, and with creating tests that happily tolerate changes to the underlying code.
Chapter 3 introduces a new requirement (six-pack), which leads to a discussion of how to decide where to start when changing code. This chapter examines the Open/Closed Principle, and then explores code smells. The chapter then defines a simple set of Flocking Rules, which guide a step-by-step refactoring of code.
Chapter 4 continues the step-by-step refactoring begun in Chapter 3. It iteratively applies the Flocking Rules, eventually stumbles across the need for the Liskov Substitution Principle, and ultimately unearths a deeply hidden abstraction.
Chapter 5 inventories the existing code for smells, chooses the most prominent one, and uses it to trigger the creation of a new class. Along the way, it takes a hard look at immutability, performance, and caching.
Chapter 6 performs a miracle that not only removes the conditionals, but also allows you to finally implement the new six-pack requirement without altering existing code.
Chapter 7 examines the tradeoffs along a continuum of six different styles of Factories. It begins by exploring a simple, hard-coded conditional, and ends with a factory whose candidate objects both self-register, and also supply the logic needed to choose them.
Chapter 8 introduces another new requirement—to vary the lyrics. It uses this requirement to introduce the idea of a programming aesthetic, or set of rules to guide you in times of uncertainty. The chapter ends with a list of specific suggestions for deciding when it’s worthwhile to voluntarily improve code.
Chapter 9 comes full circle and returns to testing. It takes advantage of the improved design to write better tests, and then uses the new tests as a spur to improve the final design.
Who Should Read This Book
The lessons in the book have been found useful by programmers with a broad range of experience, from rank novice through grizzled veteran. Despite what one might predict, novices often have an easier time with this material. As they are unencumbered by prior knowledge, their minds are open, and easily absorb these ideas.
It’s the veterans who struggle. Their habits are deeply ingrained. They know themselves to be good at programming. They feel quick, and efficient, and so resist new techniques, especially when those techniques temporarily slow them down.
This book will be useful if you are a veteran, but it cannot be denied that it teaches programming techniques that likely contradict your current practice. Changing entrenched ideas can be painful. However, you cannot make informed decisions about the value of new ideas unless you thoroughly understand them, and to understand them you must commit, wholeheartedly, to learning them.
Therefore, if you are a veteran, it’s best to adopt the novice mindset before reading on. Set aside prior beliefs, and dedicate yourself to what follows. While reading, resist the urge to resist. Read the entire book, work the problems, and only then decide whether to integrate these ideas into your daily practice.
Before You Read This Book
You’ll learn more from this book if you spend 30 minutes working on the "99 Bottles of Beer" problem before starting to read. See the appendix for instructions.
If you just want to read on but you don’t know JavaScript, have no fear. Your purchase of this book entitles you to all variants (Ruby, JavaScript, PHP, and Python), and each language variant comes in beer and milk flavors. Every combination of variant and flavor was available for download during your purchase, and one of them should suit.
Regardless of which version you read, be assured that this book is not about any specific language or beverage; it’s about object-oriented programming and design. The technical content of every version is essentially the same.
How To Read This Book
The chapters build upon one another, and so should be read in order. While isolated sections may be useful, the whole is more than the sum of its parts. The ideas gain power in relation to one another.
To get the most from the book, work the code samples as you read along. With active participation, you’ll learn more, understand better, and retain longer. While reading has value, doing has more.
Code Examples
The code examples in this version of the book are written in JavaScript. The source code shown in the book is on GitHub. The majority of code listings are extracted from this repository; and for those, the listing numbers link to the associated code in the repo.
The exercises rely on Jest.
Errata
A current list of errata is located at sandimetz.com/99bottles-errata. If you find additional errors, please email them to errata@99bottlesbook.com.
About the Authors
Sandi Metz
Sandi is the author of Practical Object-Oriented Design in Ruby. She has thirty years of experience working on large object-oriented applications. She’s spoken about programming, object-oriented design and refactoring at numerous conferences including Agile Alliance Technical Conference, Craft Conf, Øredev, RailsConf, and RubyConf. She believes in simple code and straightforward explanations, and is the proud recipient of a Ruby Hero award for her contribution to the Ruby community. She prefers working software, practical solutions and lengthy bicycle trips (not necessarily in that order). Find out more about Sandi at sandimetz.com.
Katrina Owen
Katrina works for GitHub as an Advocate on the Open Source team. Katrina has ten years of experience and works primarily in Go and Ruby. She is the creator of exercism.org, a platform for programming skill development in more than 30 languages. She’s spoken about refactoring and open source at international conferences such as NordicRuby, Mix-IT, Software Craftsmanship North America, OSCON, Bath Ruby and RailsConf. She received a Ruby Hero award for her contribution to the Ruby community. When programming, her focus is on automation, workflow optimization, and refactoring. Find out more about Katrina at exercism.github.io/kytrinyx.
TJ Stankus
TJ works as a software developer for boldfacet LLC and co-instructs software design courses with Sandi. He began his programming career over 20 years ago by accident. By hacking together WordPerfect macros to streamline his job as a proofreader, he discovered he loved programming as much as any creative activity he’d ever pursued. He has worked in mobile applications and back-end web development. He even wrote an SMTP server back when that seemed like a good idea. Today, he works primarily with Elixir and Ruby. His main interests lie not in specific programming languages, but in the essential design ideas that span programming languages and paradigms. Find out more about TJ at tj.stank.us.
About the Translators
Tom Stuart
The JavaScript translation was done by Tom Stuart. Tom is a computer scientist, programmer and technical leader. He’s the former CTO of FutureLearn and Econsultancy. He has lectured on optimising compilers at the University of Cambridge and written about technology for the Guardian.
Tom is the proud author of Understanding Computation, which was published by O’Reilly in 2013.
Matthew Fonda
Matthew Fonda provided deeply thoughtful and extremely helpful guidance about how to think about PHP and OO. Matthew is CTO at eNotes.com, where he has spent the past 15 years building a platform to help students learn. During his time at eNotes, he has learned firsthand the importance of building codebases that are easy to change over time, and is more certain than ever that the answer to every question in software development is "it depends". Matthew is a longtime member of the PHP community and occasional contributor to PHP’s documentation. When not at the computer, you can find Matthew snowboarding in the mountains of the Pacific Northwest.
The Stocktons
Brothers Dave and Dann Stockton spent countless hours pondering the initial PHP translation of the 1st edition. Theirs was the first attempt at transforming the book to use another programming language, and as such they suffered all the pain one might imagine. We are eternally grateful for their efforts and contributions.
The PHP shown in the book was written by Katrina, with the generous input of Matthew, Dave and Dann.
Katrina Owen Katrina Owen is not only an author of this book, but also wrote the Python translation.
Introduction
This book creates a simple solution to the "99 Bottles of Beer" song problem, and then applies a series of refactorings to improve the design of the code.
Put that way, the topic sounds so painfully obvious that one might reasonably wonder if this entire tome could be replaced by a few samples of code. These refactoring "end points" would be a fraction of the size of this book, and a vastly quicker read. Unfortunately, they would teach you almost nothing about programming. Writing code is the process of working your way to the next stable end point, not the end point itself. You don’t know the answer in advance, but instead, you are seeking it.
This book documents every step down every path of code, and so provides a guided-tour of the decisions made along the way. It not only shows how good code looks when it’s done, it reveals the thoughts that produced it. It aims to leave nothing out. It flings back the veil behind which sausage is being made.
A few final notes before diving into the book proper.
The chapters that follow apply a general, broad solution to a specific, narrow problem. The authors cheerfully stipulate to the fact that you are unlikely to encounter the "99 Bottles of Beer" song in your daily work, and that problems of similar size are best solved very simply. For the purposes of this book, "99 Bottles" is convenient because it’s simultaneously easily understandable and surprisingly complex, and so provides an expedient stand-in for larger problems. Once you understand the solutions here, you’ll be able to apply them to the much larger real world.
Also, the book’s code examples generally adhere to accepted style guidelines, but they occasionally indulge in extra line breaks. This means that a bit of code that you might expect to see on one line is instead spread over two. These preemptive breaks allow smaller devices to display code listings without arbitrarily wrapping lines. They are for reading expediency, and not an endorsement of this style.
With that, on to the book.
1. Rediscovering Simplicity
When you were new to programming you wrote simple code. Although you may not have appreciated it at the time, this was a great strength. Since then, you’ve learned new skills, tackled harder problems, and produced increasingly complex solutions. Experience has taught you that most code will someday change, and you’ve begun to craft it in anticipation of that day. Complexity seems both natural and inevitable.
Where you once optimized code for understandability, you now focus on its changeability. Your code is less concrete but more abstract—you’ve made it initially harder to understand in hopes that it will ultimately be easier to maintain.
This is the basic promise of Object-Oriented Design (OOD): that if you’re willing to accept increases in the complexity of your code along some dimensions, you’ll be rewarded with decreases in complexity along others. OOD doesn’t claim to be free; it merely asserts that its benefits outweigh its costs.
Design decisions inevitably involve trade-offs. There’s always a cost. For example, if you’ve duplicated a bit of code in many places, the Don’t Repeat Yourself (DRY) principle tells you to extract the duplication into a single common method and then invoke this new method in place of the old code. DRY is a great idea, but that doesn’t mean it’s free. The price you pay for DRYing out code is that the invoker of the new method no longer knows the result, only the message it should send. If you’re willing to pay this price, that is, you are willing to be ignorant of the actual behavior, the reward you reap is that when the behavior changes, you need alter your code in only one place. The argument that OOD makes is that this bargain will save you money.
Did you divide one large class into many small ones? You can now reuse the new classes independently of one another, but it’s no longer obvious how they fit together for the original case. Have you injected a dependency instead of hard-coding the class name of a collaborator? The receiver can now freely depend on new and previously unforeseen objects, but it must remain ignorant of their actual class.
The examples above change code by increasing its level of abstraction. DRYing out code inserts a level of indirection between the place that uses behavior and the place that defines it. Breaking one large class into many forces the creation of something new to embody the relationship between the pieces. Injecting a dependency transforms the receiver into something that depends on an abstract role rather than a concrete class.
Each of these design choices has costs, and it only makes sense to pay these costs if you also accrue some offsetting benefits. Design is thus about picking the right abstractions. If you choose well, your code will be expressive, understandable and flexible, and everyone will love both it and you. However, if you get the abstractions wrong, your code will be convoluted, confusing, and costly, and your programming peers will hate you.
Unfortunately, abstractions are hard, and even with the best of intentions, it’s easy to get them wrong. Well-meaning programmers tend to over-anticipate abstractions, inferring them prematurely from incomplete information. Early abstractions are often not quite right, and therefore they create a catch-22.[1] You can’t create the right abstraction until you fully understand the code, but the existence of the wrong abstraction may prevent you from ever doing so. This suggests that you should not reach for abstractions, but instead, you should resist them until they absolutely insist upon being created.
This book is about finding the right abstraction. This first chapter starts by peeling away the fog of complexity and defining what it means to write simple code.
1.1. Simplifying Code
The code you write should meet two often-contradictory goals. It must remain concrete enough to be understood while simultaneously being abstract enough to allow for change.
Imagine a continuum with "most concrete" at one end and "most abstract" at the other. Code at the
concrete end might be expressed as a single long procedure full of if statements. Code at the
abstract end might consist of many classes, each with one method containing a single line of code.
The best solution for most problems lies not at the extremes of this continuum, but somewhere in the middle. There’s a sweet spot that represents the perfect compromise between comprehension and changeability, and it’s your job as a programmer to find it.
This section discusses four different solutions to the "99 Bottles of Beer" problem. These solutions vary in complexity and thus illustrate different points along this continuum.
You must now make a decision. As you were forewarned in the preface, the best way to learn from this book is to work the exercises yourself. If you continue reading before solving the problem in your own way, your ideas will be contaminated by the code that follows. Therefore, if you plan to work along, go do the 99 Bottles exercise now. When you’re finished, you’ll be ready to examine the following four solutions.
1.1.1. Incomprehensibly Concise
Here’s the first of four different solutions to the "99 Bottles" song.
1 class Bottles {
2 song() {
3 return this.verses(99, 0);
4 }
5
6 verses(hi, lo) {
7 return downTo(hi, lo).map(n => this.verse(n)).join('\n');
8 }
9
10 verse(n) {
11 return (
12 `${n === 0 ? 'No more' : n} bottle${n === 1 ? '' : 's'}` +
13 ' of beer on the wall, ' +
14 `${n === 0 ? 'no more' : n} bottle${n === 1 ? '' : 's'} of beer.\n` +
15 `${n > 0 ? `Take ${n > 1 ? 'one' : 'it'} down and pass it around`
16 : 'Go to the store and buy some more'}, ` +
17 `${n-1 < 0 ? 99 : n-1 === 0 ? 'no more' : n-1} bottle${n-1 === 1 ? '' : 's'}`+
18 ' of beer on the wall.\n'
19 );
20 }
21 }
22
23 // Here is the definition of the downTo helper function
24 // used above. It will be omitted from subsequent listings.
25
26 const downTo = (max, min) => {
27 const numbers = [];
28 for (let n = max; n >= min; n--) {
29 numbers.push(n);
30 }
31 return numbers;
32 };This first solution embeds a great deal of logic into the verse string. The code above performs a neat trick. It manages to be concise to the point of incomprehensibility while simultaneously retaining loads of duplication. This code is hard to understand because it is inconsistent and duplicative, and because it contains hidden concepts that it does not name.
Consistency
The conditionals are confusing. Most use the simple ternary form, as on line 12:
n === 0 ? 'No more' : nBut some nest a ternary within a ternary, as on line 17, which is best left without comment:
n-1 < 0 ? 99 : n-1 === 0 ? 'no more' : n-1Nested conditionals make code harder for humans to parse; this style of coding raises costs without providing benefits.
Duplication
The code duplicates both data and logic. Having multiple copies of the strings "of beer" and "on the
wall" isn’t great, but at least string duplication is easy to see and understand.
Logic, however, is harder to comprehend than data, and duplicated logic is doubly so. Of course, if
you want to achieve maximum confusion, you can interpolate duplicated logic inside strings,
as does the verse method above.
For example, "bottle" pluralization is done in three places. The code to do this is identical in two of the places, on lines 12 and 14:
n === 1 ? '' : 's'But later, on line 17, the pluralization logic is subtly different.
Suddenly it’s not n that matters, but
n-1:
n-1 === 1 ? '' : 's'Duplication of logic suggests that there are concepts hidden in the code that are not yet visible
because they haven’t been isolated and named. The need to sometimes say "bottle" and other times
say "bottles" means something, and the need to sometimes use
n and other times use
n-1 means something else. The code gives no
clue about what these meanings might be; you’re left to figure this out for yourself.
Names
The most obvious point to be made about the names in the verse method of Listing 1.1: Incomprehensibly Concise is that there
aren’t any. The verse string contains embedded logic. Each bit of logic serves some purpose, and
it is up to you to construct a mental map of what these purposes might be.
This code would be easier to understand if it did not place that burden upon you, the intrepid
reader. The logic that’s hidden inside the verse string should be dispersed into
methods, and verse should fill itself with values by sending messages.
Creating a method requires identifying the code you’d like to extract and deciding on a method name. This, in turn, requires naming the concept, and naming things is just plain hard. In the case above, it’s especially hard. This code not only contains many hidden concepts, but those concepts are mixed together, conflated, such that their individual natures are obscured. Combining many ideas into a small section of code makes it difficult to isolate and name any single concept.
When you first write a piece of code, you obviously know what it does. Therefore, during initial development, the price you pay for poor names is relatively low. However, code is read many more times than it is written, and its ultimate cost is often very high and paid by someone else. Writing code is like writing a book; your efforts are for other readers. Although the struggle for good names is painful, it is worth the effort if you wish your work to survive to be read. Code clarity is built upon names.
Problems with consistency, duplication, and naming conspire to make the code in Listing 1.1: Incomprehensibly Concise likely to be costly.
Note that the above assertion is, at this point, an unsupported opinion. The best way to judge code would be to compare its value to its cost, but unfortunately it’s hard to get good data. Judgments about code are therefore commonly reduced to individual opinion, and humans are not always in accord. There’s no perfect solution to this problem, but the Judging Code section, later in this chapter, suggests ways to acquire empirical data about the goodness of code.
Independent of all judgment about how well a bit of code is arranged, code is also charged with doing what it’s supposed to do now as well as being easy to alter so that it can do more later. While it’s difficult to get exact figures for value and cost, asking the following questions will give you insight into the potential expense of a bit of code:
-
How difficult was it to write?
-
How hard is it to understand?
-
How expensive will it be to change?
The past ("was it") is a memory, the future ("will it be") is imaginary, but the present ("is it") is true right now. The very act of looking at a piece of code declares that you wish to understand it at this moment. Questions 1 and 3 above may or may not concern you, but question 2 always applies.
Code is easy to understand when it clearly reflects the problem it’s solving, and thus openly exposes that problem’s domain. If Listing 1.1: Incomprehensibly Concise openly exposed the "99 Bottles" domain, a brief glance at the code would answer these questions:
-
How many verse variants are there?
-
Which verses are most alike? In what way?
-
Which verses are most different, and in what way?
-
What is the rule to determine which verse comes next?
These questions reflect core concepts of the problem, yet none of their answers are apparent in this solution. The number of variants, the difference between the variants, and the algorithm for looping are distressingly obscure. This code does not reflect its domain, and therefore you can infer that it was difficult to write and will be a challenge to change. If you had to characterize the goal of the writer of Listing 1.1: Incomprehensibly Concise, you might suggest that their highest priority was brevity. Brevity may be the soul of wit, but it quickly becomes tedious in code.
Incomprehensible conciseness is clearly not the best solution for the "99 Bottles" problem. It’s time to examine one that’s more verbose.
1.1.2. Speculatively General
This next solution errs in a different direction. It does many things well but can’t resist indulging in unnecessary complexity. Have a look at the code below:
1 const NoMore = verse =>
2 'No more bottles of beer on the wall, ' +
3 'no more bottles of beer.\n' +
4 'Go to the store and buy some more, ' +
5 '99 bottles of beer on the wall.\n';
6
7 const LastOne = verse =>
8 '1 bottle of beer on the wall, ' +
9 '1 bottle of beer.\n' +
10 'Take it down and pass it around, ' +
11 'no more bottles of beer on the wall.\n';
12
13 const Penultimate = verse =>
14 '2 bottles of beer on the wall, ' +
15 '2 bottles of beer.\n' +
16 'Take one down and pass it around, ' +
17 '1 bottle of beer on the wall.\n';
18
19 const Default = verse =>
20 `${verse.number()} bottles of beer on the wall, ` +
21 `${verse.number()} bottles of beer.\n` +
22 'Take one down and pass it around, ' +
23 `${verse.number() - 1} bottles of beer on the wall.\n`;
24
25 class Bottles {
26 song() {
27 return this.verses(99, 0);
28 }
29
30 verses(finish, start) {
31 return downTo(finish, start)
32 .map(verseNumber => this.verse(verseNumber))
33 .join('\n');
34 }
35
36 verse(number) {
37 return this.verseFor(number).text();
38 }
39
40 verseFor(number) {
41 switch (number) {
42 case 0: return new Verse(number, NoMore);
43 case 1: return new Verse(number, LastOne);
44 case 2: return new Verse(number, Penultimate);
45 default: return new Verse(number, Default);
46 }
47 }
48 }
49
50 class Verse {
51 constructor(number, lyrics) {
52 this._number = number;
53 this.lyrics = lyrics;
54 }
55
56 number() {
57 return this._number;
58 }
59
60 text() {
61 return this.lyrics(this);
62 }
63 }If you find this code less than clear, you’re not alone. It’s confusing enough to warrant an explanation, but because the explanation naturally reflects the code, it’s confusing in its own right. Don’t worry if the following paragraphs muddle things further. Their purpose is to help you appreciate the complexity rather than understand the details.
The code above first defines four anonymous functions (lines 1, 7, 13, and 19) and saves them as constants (NoMore,
LastOne,
Penultimate, and
Default). Notice that each function takes argument verse but only
Default actually refers to it. The code then defines the
song and verses methods. Next comes the verse method, which
passes the current verse number to verseFor and sends
text to the result (line 37). This is the line of code that
returns the correct string for a verse of the song.
Notice that each function takes argument verse but only
Default actually refers to it. The code then defines the
song and verses methods. Next comes the verse method, which
passes the current verse number to verseFor and sends
text to the result (line 37). This is the line of code that
returns the correct string for a verse of the song.
Things get more interesting in verseFor, but before
pondering that method, look ahead to the Verse class on line 50. Verse instances are initialized with two arguments,
number and
lyrics, and they respond to two messages, number
and text. The number method simply returns the verse number that was passed
during construction. The text method is more complicated; it
calls lyrics, passing
this as an argument.
If you now return to verseFor and examine lines 42-45, you can see that when instances of Verse are created, the
number argument is a verse number and the
lyrics argument is one of the anonymous functions. The
verseFor method gets invoked for every verse of the song,
and therefore, one hundred instances of Verse will be created, each containing a verse
number and the function that corresponds to that number.
To summarize, sending verse(number) to an
instance of Bottles invokes verseFor(number),
which uses the value of number to select the
correct anonymous function on which to create and return an instance of
Verse. The verse method then sends text to the returned
Verse, which in turn calls the function, passing this as an
argument. This invokes the function, which may or may not actually use the
argument that was passed. Regardless, executing the function returns a
string that contains the lyrics for one verse of the song.
You can be forgiven if you suspect that this is unduly complicated. It is. However, it’s curious that despite this complexity, Listing 1.2: Speculatively General does a much better job than Listing 1.1: Incomprehensibly Concise of answering the domain questions:
-
How many verse variants are there?
There are four verse variants (they start on lines 1, 7, 13, and 19 above). -
Which verses are most alike? In what way?
Verses 3-99 are most alike (as evidenced by the fact that all are produced by theDefaultvariant). -
Which verses are most different? In what way?
Verses 0, 1 and 2 are clearly different from 3-99, although it’s not obvious in what way. -
What is the rule to determine which verse should be sung next?
Buried deep within theNoMorefunction is a hard-coded "99," which might cause one to infer that verse 99 follows verse 0.
This solution’s answers to the first three questions above are quite an improvement over those of Listing 1.1: Incomprehensibly Concise. However, all is not perfect; it still does poorly on the value/cost questions:
-
How difficult was it to write?
There’s far more code here than is needed to pass the tests. This unnecessary code took time to write. -
How hard is it to understand?
The many levels of indirection are confusing. Their existence implies necessity, but you could study this code for a long time without discerning why they are needed. -
How expensive will it be to change?
The mere fact that indirection exists suggests that it’s important. You may feel compelled to understand its purpose before making changes.
As you can see from these answers, this solution does a good job of exposing core concepts, but does a bad job of being worth its cost. This good job/bad job divide reflects a fundamental fissure in the code.
Aside from the song and verses methods, the code does two basic things.
First, it defines templates for each kind of verse (lines 1-23), and
second, it chooses the appropriate template for a specific verse number and renders that verse’s
lyrics (lines 36-63).
Notice that the verse templates contain all of the information needed to answer the domain questions.
There are four templates, and therefore, there must be four verse variants. The
Default template handles verses 3 through 99, so these
verses are clearly most alike. Verses 0, 1, and 2 have their own special templates, so each must be
unique. The four templates (if you ignore the fact that they’re stored in anonymous functions) are very straightforward, which makes answering the
domain questions easy.
But it’s not the templates that are costly; it’s the code that chooses a template and renders the lyrics for a verse. This choosing/rendering code is overly complicated, and while complexity is not forbidden, it is required to pay its own way. In this case, complexity does not.
Instead of 1) defining a function to hold a template, 2) creating a new
object to hold the function, and 3) invoking the function with this as an argument,
the code could merely have put each of the four templates into a method and then used the switch statement on lines 42-45 to invoke the correct one. Neither the
functions nor the Verse class are needed, and the route
between them is a series of pointless jumps through needless hoops.
Given the obvious superiority of this alternative implementation, how on earth did the "calling an anonymous function" variant come about? At this remove,[2] it’s difficult to be certain of the motivation, but the code gives the impression that its author feared that the logic for selecting or invoking a template would someday need to change, and so added levels of indirection in a misguided attempt to protect against that day.
They did not succeed. Relative to the alternative, Listing 1.2: Speculatively General is harder to understand without being easier to change. The additional complexity does not pay off. The author may have acted with the best of intentions, but somewhere along the way, their commitment to the plan overcame good sense.
Programmers love clever code. It’s like a neat card trick that uses sleight of hand and misdirection to make magic. Writing it, or suddenly understanding it, supplies a little burst of appreciative pleasure. However, this very pleasure distracts the eye and seduces the mind, and allows cleverness to worm its way into inappropriate places.
You must resist being clever for its own sake. If you are capable of conceiving and implementing a solution as complex as Listing 1.2: Speculatively General, it is incumbent upon you to accept the harder task and write simpler code.
Neither Listing 1.2: Speculatively General nor Listing 1.1: Incomprehensibly Concise is the best solution for "99 Bottles". Perhaps, as was true for porridge, the third solution will be just right.[3]
1.1.3. Concretely Abstract
This solution valiantly attempts to name the concepts in the domain. Here’s the code:
1 class Bottles {
2 song() {
3 return this.verses(99, 0);
4 }
5
6 verses(bottlesAtStart, bottlesAtEnd) {
7 return downTo(bottlesAtStart, bottlesAtEnd)
8 .map(bottles => this.verse(bottles))
9 .join('\n');
10 }
11
12 verse(bottles) {
13 return new Round(bottles).toString();
14 }
15 }
16
17 class Round {
18 constructor(bottles) {
19 this.bottles = bottles;
20 }
21
22 toString() {
23 return this.challenge() + this.response();
24 }
25
26 challenge() {
27 return (
28 capitalize(this.bottlesOfBeer()) + ' ' +
29 this.onWall() + ', ' +
30 this.bottlesOfBeer() + '.\n'
31 );
32 }
33
34 response() {
35 return (
36 this.goToTheStoreOrTakeOneDown() + ', ' +
37 this.bottlesOfBeer() + ' ' +
38 this.onWall() + '.\n'
39 );
40 }
41
42 bottlesOfBeer() {
43 return (
44 this.anglicizedBottleCount() + ' ' +
45 this.pluralizedBottleForm() + ' of ' +
46 this.beer()
47 );
48 }
49
50 beer() {
51 return 'beer';
52 }
53
54 onWall() {
55 return 'on the wall';
56 }
57
58 pluralizedBottleForm() {
59 return this.isLastBeer() ? 'bottle' : 'bottles';
60 }
61
62 anglicizedBottleCount() {
63 return this.isAllOut() ? 'no more' : this.bottles.toString();
64 }
65
66 goToTheStoreOrTakeOneDown() {
67 if (this.isAllOut()) {
68 this.bottles = 99;
69 return this.buyNewBeer();
70 } else {
71 const lyrics = this.drinkBeer();
72 this.bottles--;
73 return lyrics;
74 }
75 }
76
77 buyNewBeer() {
78 return 'Go to the store and buy some more';
79 }
80
81 drinkBeer() {
82 return `Take ${this.itOrOne()} down and pass it around`;
83 }
84
85 itOrOne() {
86 return this.isLastBeer() ? 'it' : 'one';
87 }
88
89 isAllOut() {
90 return this.bottles === 0;
91 }
92
93 isLastBeer() {
94 return this.bottles === 1;
95 }
96 }
97
98 // Here is the definition of the capitalize helper function
99 // used above. It will be omitted from subsequent listings.
100
101 const capitalize =
102 string => string.charAt(0).toUpperCase() + string.slice(1);This solution is characterized by having many small methods. This is normally a good thing, but somehow in this case it’s gone badly wrong. Have a look at how this solution does on the domain questions:
-
How many verse variants are there?
It’s almost impossible to tell. -
Which verses are most alike? In what way?
Ditto. -
Which verses are most different? In what way?
Ditto. -
What is the rule to determine which verse should be sung next?
Ditto.
It fares no better on the value/cost questions.
-
How difficult was it to write?
Difficult. This clearly took a fair amount of thought and time. -
How hard is it to understand?
The individual methods are easy to understand, but despite this, it’s tough to get a sense of the entire song. The parts don’t seem to add up to the whole. -
How expensive will it be to change?
While changing the code inside any individual method is cheap, in many cases, one simple change will cascade and force many other changes.
It’s obvious that the author of this code was committed to doing the right thing, and that they carefully followed the Red, Green, Refactor style of writing code. The various strings that make up the song are never repeated—it looks as though these strings were refactored into separate methods at the first sign of duplication.
The code is DRY, and DRYing out code should reduce costs. DRY promises that if you put a chunk of code into a method and then invoke that method instead of duplicating the code, you will save money later if the behavior of that chunk changes. Recognize, though, that DRYing out code is not free. It adds a level of indirection, and layers of indirection make the details of what’s happening harder to understand. DRY makes sense when it reduces the cost of change more than it increases the cost of understanding the code.
The Don’t Repeat Yourself principle, like all principles of object-oriented design, is completely true. However, despite that fact that the code above is DRY, there are many ways in which it’s expensive to change.
One of many possible examples is the beer method on line 50.
This method returns the string "beer," which occurs nowhere else in the code. To change the drink to
"Kool-Aid," you need only change line 51 to return "Kool-Aid" instead of
"beer." As this one small change is all that’s needed to meet the "Kool-Aid" requirement, on the
surface, DRY has fulfilled its promise. However, step back a minute and consider the resulting method:
beer() {
return 'Kool-Aid';
}Or ponder some of the other method names:
bottlesOfBeer() {
buyNewBeer() {
drinkBeer() {
isLastBeer() {In light of the "Kool-Aid" change, these names are terribly confusing. These method names no longer make sense where they are defined, and they are totally misleading in places where they are used. To mitigate this confusion, you not only have to change "beer" to "Kool-Aid" inside this method, but you also have to make the same change to every method name that includes the word "beer" and then again to every sender of one of those messages.
This small change in requirements forces a change in many places, which is exactly the problem DRY promises to avoid. The fault here, however, lies not with the DRY principle, but with the names of the methods.
When you choose beer as the name of a method that returns the string "beer," you’ve
named the method after what it does right now. Unfortunately, when you name a method after its current
implementation, you can never change that internal implementation without ruining the method name.
You should name methods not after what they do, but after what they mean, what they represent in the context of your domain. If you were to ask your customer what "beer" is in the context of the "99 Bottles" song, they would not answer "Beer is the beer," they would say something like "Beer is the thing you drink" or "Beer is the beverage."
"Beer" and "Kool-Aid" are kinds of beverages; the word "beverage" is one level of abstraction higher
than "beer." Naming the method at this slightly higher level of abstraction isolates the code from
changes in the implementation details. If you choose beverage for the method name, going
from:
beverage() {
return 'beer';
}to:
beverage() {
return 'Kool-Aid';
}makes perfect sense and requires no other change.
Listing 1.3: Concretely Abstract contains many small methods, and the strings that make up the song are completely DRY. These two things exert a force for good that should result in code that’s easy to change. However, in Concretely Abstract, this force is overcome by the high cost of dealing with methods that are named at the wrong level of abstraction. These method names raise the cost of change.
Therefore, one lesson to be gleaned from this solution is that you should name methods after the concept they represent rather than how they currently behave. However, notice that even if you edited the code to improve every method name, this code still isn’t quite right.
Changing the name of the beer method to beverage makes it easy to replace the
string "beer" with the string "Kool-Aid" but does nothing to improve this code’s score on the
domain questions. The problem goes far deeper than having methods with inadequate names. It’s not
just the names that are wrong, but the methods themselves. Many methods in this code represent the wrong
abstractions.
The challenge of identifying the right abstractions is explored in future chapters, but meanwhile, it’s time to consider one more solution.
1.1.4. Shameless Green
None of the solutions shown thus far do very well on the value/cost questions. Incomprehensibly Concise cares only for terseness. Speculatively General tries for extensibility but achieves unwarranted complexity. The heart of Concretely Abstract is in the right place, but it can’t get its feet out of the mud.
Solving the "99 Bottles" problem in any of these ways requires more effort than is necessary and results in more complexity than is needed. These solutions cost too much; they do too many of the wrong things and too few of the right.
Speculatively General and Concretely Abstract were both written with an eye toward reducing future costs, and it is distressing to see good intentions fail so spectacularly. It’s a particular shame that the abstractions are wrong because given the opportunity to do so, the code is completely willing to reveal abstractions that are right. The failure here is not bad intention—it’s insufficient patience.
This next example is patient and so provides an antidote for all that has come before. The following solution is known as Shameless Green:
1 class Bottles {
2 song() {
3 return this.verses(99, 0);
4 }
5
6 verses(upper, lower) {
7 return downTo(upper, lower)
8 .map(i => this.verse(i))
9 .join('\n');
10 }
11
12 verse(number) {
13 switch (number) {
14 case 0:
15 return (
16 'No more bottles of beer on the wall, ' +
17 'no more bottles of beer.\n' +
18 'Go to the store and buy some more, ' +
19 '99 bottles of beer on the wall.\n'
20 );
21 case 1:
22 return (
23 '1 bottle of beer on the wall, ' +
24 '1 bottle of beer.\n' +
25 'Take it down and pass it around, ' +
26 'no more bottles of beer on the wall.\n'
27 );
28 case 2:
29 return (
30 '2 bottles of beer on the wall, ' +
31 '2 bottles of beer.\n' +
32 'Take one down and pass it around, ' +
33 '1 bottle of beer on the wall.\n'
34 );
35 default:
36 return (
37 `${number} bottles of beer on the wall, ` +
38 `${number} bottles of beer.\n` +
39 'Take one down and pass it around, ' +
40 `${number-1} bottles of beer on the wall.\n`
41 );
42 }
43 }
44 }The most immediately apparent quality of this code is how very simple it is. There’s nothing tricky here. The code is gratifyingly easy to comprehend. Not only that, despite its lack of complexity, this solution does extremely well on the domain questions.
-
How many verse variants are there?
Clearly, four. -
Which verses are most alike? In what way?
3-99, where only the verse number varies. -
Which verses are most different? In what way?
0, 1 and 2 are different from 3-99, though figuring out how requires parsing strings with your eyes. -
What is the rule to determine which verse should be sung next?
This is still not explicit. The 0 verse contains a deeply buried, hard-coded 99.
These answers are identical to those achieved by Listing 1.2: Speculatively General. Shameless Green and Speculatively General differ, though, in how they compare on the value/cost questions. Shameless Green is a substantial improvement.
-
How difficult was this to write?
It was easy to write. -
How hard is it to understand?
It is easy to understand. -
How expensive will it be to change?
It will be cheap to change. Even though the verse strings are duplicated, if one verse changes it’s easy to keep the others in sync.
By the criteria that have been established, Shameless Green is clearly the best solution, yet almost no one writes it. It feels embarrassingly easy, and is missing many qualities that you expect in good code. It duplicates strings and contains few named abstractions.
Most programmers have a powerful urge to do more, but sometimes it’s best to stop right here. If you were charged with writing the code to produce the lyrics to the 99 Bottles song, it is difficult to imagine fulfilling that requirement in a more cost-effective way.
The Shameless Green solution is disturbing because, although the code is easy to understand, it makes no provision for change. In this particular case, the song is so unlikely to change that betting that the code is "good enough" should pay off. However, if you pretend that this problem is a proxy for a real, production application, the proper course of action is not so clear.
When you DRY out duplication or create a method to name a bit of code, you add levels of indirection that make it more abstract. In theory these abstractions make code easier to understand and change, but in practice they often achieve the opposite. One of the biggest challenges of design is knowing when to stop, and deciding well requires making judgments about code.
1.2. Judging Code
You now have access to five different solutions to the "99 Bottles of Beer" problem; the four listed in the preceding section and the one you wrote yourself.
Which is best?
You likely have an opinion on this question—one which, granted, may have been swayed by the commentary above. However, independent of that gentle influence, the sum of your experiences and expectations predispose you to assess the goodness of code in your own unique way.
You judge code constantly. Writing code requires making choices; the choices you make reflect personal, internalized criteria. You intend to write "good" code and if, in your estimation, you’ve written "bad" code, you are clearly aware that you’ve done so. Regardless of how implicit, unachievable, or unhelpful they may be, you already have rules about code.
While having standards of any sort is a virtue, the chance of achieving your standards is improved if they are explicit and quantifiable. Answering the question "What makes code good?" thus requires defining goodness in concrete and actionable ways.
This is harder than one might think.
1.2.1. Evaluating Code Based on Opinion
You’d think that by now, there would exist a universally agreed-upon definition of good code that could unambiguously guide our programming behavior. The unfortunate truth is that not only are there a multitude of definitions, but these definitions generally describe how code looks when it’s done without providing any concrete guidance about how to get there.
Just as "Everybody complains about the weather but nobody does anything about it,"[4] everyone has an opinion about what good code looks like, but those opinions usually don’t tell us what action to take to create it. Here are a few definitions of clean code. Notice that they could describe art or wine as easily as software.
I like my code to be elegant and efficient.
inventor of C++
Clean code is … full of crisp abstractions …
author of Object Oriented Analysis and Design with Applications
Clean code was written by someone who cares.
author of Working Effectively with Legacy Code
Your own definition probably follows along these same lines. Any pile of code can be made to work; good code not only works, but is also simple, understandable, expressive and changeable.
The problem with these definitions is that although they accurately describe how good code looks once it’s written, they give no help with achieving this state, and provide little guidance for choosing between competing solutions. The attributes they use to describe good code are qualitative, not quantitative.
What does it mean to be "elegant?" What makes an abstraction "crisp?" Despite the fact that these definitions are undeniably correct, none are precise in a measurable way. This lack of precision means that well-meaning programmers can hold identically high standards and still have significant disagreements about relative goodness. Thus, we argue fruitlessly about code.
Since form follows function, good code can also be defined simply, and somewhat circularly, as that which provides the highest value for the lowest cost. Our sense of elegance, expressiveness and simplicity is an outgrowth of our experiences when reading and modifying code. Code that is easy to understand and a pleasure to extend naturally feels simple and elegant.
If you could identify and measure these qualities, you could seek after them diligently and deliberately. Therefore, although your opinions about code matter, you would be well served by facts.
1.2.2. Evaluating Code Based on Facts
A "metric" is a measure of some quality of code. Metrics are, obviously, created by people, so one could argue that they merely express one individual’s opinion. That assertion, however, vastly understates their worth. Measures that rise to become metrics are backed by research that has stood the test of time. They’ve been scrutinized by many people over many years. You can think of metrics as crowd-sourced opinions about the quality of code.
If you apply the same metric to two different pieces of source code, you can then compare that code (at least in terms of what the metric measures) by comparing the resulting numbers. While it’s possible to disagree with the premise of a specific metric, and to insist that the thing it measures isn’t useful, the rules of mathematics require all to concede that the numbers produced by metrics are facts.
It would be extremely handy to have agreed-upon facts with which to compare code. In search of these facts, this section examines three different metrics: Source Lines of Code, Cyclomatic Complexity, and ABC.
Source Lines of Code
In the days of yore, the desire for reproducible, reliable information about the cost of developing applications led to the creation of a metric known simply as Source Lines of Code (SLOC, sometimes shortened to just LOC). This one number has been used to predict the total effort needed to develop software, to measure the productivity of those who write it, and to predict the cost of maintaining it.
The metric has the advantage of being easily garnered and reproduced, but suffers from many flaws.
Using SLOC to predict the development effort needed for a new project is done by counting the SLOC of existing projects for which total effort is known, deciding which of those existing projects the new project most resembles, and then running a cost estimation model to make the prediction. If the person doing the estimating is correct about which existing project(s) the new project most closely resembles, this prediction may be accurate.
Measuring programmer productivity by counting lines of code assumes that all programmers write equally efficient code. However, novice programmers are often far more verbose than those with more experience. Despite the fact that novices write more code to produce less function, by this metric, they can seem more productive.
While the cost of maintenance is related to the size of an application, the way in which code is organized also matters. It is cheaper to maintain a well-designed application than it is to maintain a pile of spaghetti-code.
SLOC numbers reflect code volume, and while it’s useful for some purposes, knowing SLOC alone is not enough to predict code quality.
Cyclomatic Complexity
In 1976, Thomas J. McCabe, Sr. published "A Complexity Measure", in which he asserted:
What is needed is a mathematical technique that will provide a quantitative basis for modularization and allow us to identify software modules that will be difficult to test or maintain.
A "mathematical technique" to identify code that is "difficult to test or maintain"—this could be the perfect tool for assessing code. In his paper, McCabe describes his Cyclomatic Complexity metric, an algorithm that counts the number of unique execution paths through a body of source code. Think of this algorithm as a little machine that ponders your code and then maps out all the possible routes through every combination of every branch of every conditional. A method with many deeply nested conditionals would score very high, while a method with no conditionals at all would score 0.
Cyclomatic complexity neither predicts application development time nor measures programmer productivity. Its desire to identify code that is difficult to test or maintain aims directly at code quality.
Cyclomatic complexity can be used in several ways. First, you can use it to compare code. If you have two variants of the same method, you can choose between them based on their cyclomatic complexity. Lower scores are better and so by extension the code with the lowest score is the best.
Next, you can use it to limit overall complexity. You can set standards for how high a score you’re willing to accept, and require explicit dispensation before allowing code to exceed this maximum.
Finally, you can use it to determine if you’ve written enough tests. Cyclomatic complexity tells you the minimum number of tests needed to cover all of the logic in the code. If you have fewer tests than cyclomatic complexity recommends, you don’t have complete test coverage.
Cyclomatic complexity sounds great, and it’s easy to see that it could be useful, but it views the world of code through a narrow lens.
Assignments, Branches and Conditions (ABC) Metric
The problem with cyclomatic complexity is that it doesn’t take everything into account. Code does more than just evaluate conditions; it also assigns values to variables and sends messages. These things add up, and as you do more and more of each, your code becomes increasingly difficult to understand.
In 1997, twenty-one years after the unveiling of cyclomatic complexity, Jerry Fitzpatrick published "Applying the ABC Metric to C, C++, and Java", in which he describes a metric that does consider more than conditionals. His ABC stands for assignments, branches and conditions, where:
-
Assignments is a count of variable assignments.
-
Branches counts not branches of an if statement (as one could forgivably infer) but branches of control, meaning function calls or message sends.
-
Conditions counts conditional logic.
Fitzpatrick describes the ABC metric as a measure of size, as if ABC is a more sophisticated version of SLOC. This is his metric so he certainly gets to say what it represents, but you will not go wrong if you think of ABC scores as reflecting cognitive as opposed to physical size. High ABC numbers indicate code that takes up a lot of mental space. In this sense, ABC is a measure of complexity. Highly complex code is difficult to understand and change, therefore ABC scores are a proxy for code quality.
At the time of writing this there are no widely adopted—or even maintained—metrics libraries for JavaScript. The JavaScript landscape changes quickly, so regardless, consider looking for tools to run against your code.
ABC scores provide an independent perspective that may challenge your ideas about complexity and design. High scores suggest that code will be hard to test and expensive to maintain. If you believe your code to be simple but the ABC score says otherwise, you should think again.
Metrics are fallible but human opinion is no more precise. Checking metrics regularly will keep you humble and improve your code.
1.2.3. Comparing Solutions
Now that you have some insight into code metrics, it’s time to ponder how the code examples shown in this chapter compare.
Since all of the solutions have virtually identical implementations for song and
verses, these can be ignored, focusing the counts on the code that is necessary for the
definition of verse.
The following table shows each solution’s total lines of code (SLOC) along with back-of-the-napkin counts of assignments, branches[5], and conditionals, and the resulting ABC[6] score.
| Solution | SLOC | Assignments | Branches | Conditionals | ABC |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Here’s a chart of the above SLOC and ABC scores.
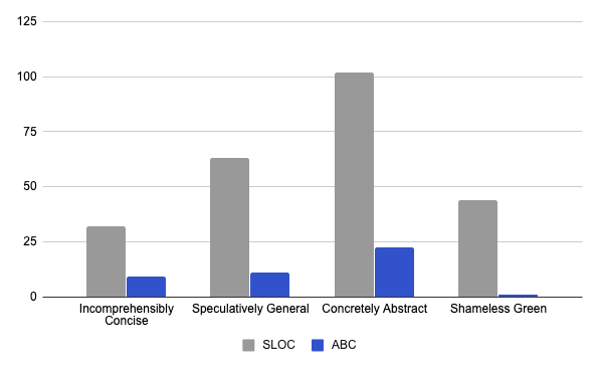
Although SLOC is not related to ABC score, both are considered a measure of size, and they appear to be roughly correlated. A larger solution in terms of SLOC is for the most part also larger in terms of its ABC score. Shameless Green is the notable exception—it’s only second lowest in SLOC, but has the lowest ABC score by a considerable margin.
Incomprehensibly Concise and Concretely Abstract are interesting in that they both have characteristically complex code, but along different axes. Incomprehensibly Concise has the fewest lines of code, but the most conditionals. It has managed to condense a lot of complexity into very few lines. In Concretely Abstract, on the other hand, the complexity lies in the branching (message sends), not so much in the conditionals. The complexity in this solution is spread across the largest number of lines of code; no single method has any significant amount of complexity.
Speculatively General is shorter than Concretely Abstract, and its complexity is spread out more evenly among assignments, branches, and conditionals.
Shameless Green scores best on all counts except SLOC. Incomprehensibly Concise is the shortest solution, but when you look at the ratio of lines of code to conditionals, Shameless Green comes out more favorably.
Incomprehensibly Concise and Shameless Green are similar in that most of their complexity is contained in a single method. Neither has assignments or branching. Despite this similarity, if you compare their SLOC scores to their conditional counts, you’ll see that they are also very different. While Incomprehensibly Concise has many conditionals relative to SLOC, Shameless Green has the opposite. Incomprehensibly Concise packs a lot of complexity into a few lines of code. Shameless Green is biased in the other direction; it has more code but is much simpler.
If your goal is to write straightforward code, these metrics point you toward Shameless Green.
1.3. Summary
As programmers grow, they get better at solving challenging problems, and become comfortable with complexity. This higher level of comfort sometimes leads to the belief that complexity is inevitable, as if it’s the natural, inescapable state of all finished code. However, there’s something beyond complexity—a higher level of simplicity. Infinitely experienced programmers do not write infinitely complex code; they write code that’s blindingly simple.
This chapter examined four possible solutions to the "99 Bottles" problem as a prelude to defining what it means to write simple code. It used metrics as a starting point, injected a bit of common sense, and landed on Shameless Green.
Shameless Green is defined as the solution that quickly reaches green while prioritizing understandability over changeability. It uses tests to drive comprehension, and patiently accumulates concrete examples while awaiting insight into underlying abstractions. It doesn’t dispute that DRY is good, rather, it believes that it is cheaper to manage temporary duplication than to recover from incorrect abstractions.
Writing Shameless Green is fast, and the resulting code might be "good enough." Most programmers find it embarrassingly duplicative, and the code is certainly not very object-oriented. However, if nothing ever changes, the most cost-effective strategy is to deploy this code and walk away.
The challenge comes when a change request arrives. Code that’s good enough when nothing ever changes may not be good enough when things do. Chapter 3 introduces just such a change, and in that chapter you’ll begin improving the code. Before moving on, however, it’s time to take a step back, and learn how to test-drive Shameless Green.
2. Test Driving Shameless Green
The previous chapter examined four solutions to the "99 Bottles" problem, and asserted that the one known as Shameless Green is best. The Shameless Green solution consists of intention-revealing, working software, and is the result of writing simple code to pass a series of pre-supplied tests.
The provenance of the code that was written in Chapter 1 is obvious, but the tests appeared without explanation. It is now time to take a step back, and investigate how to create tests that lead to Shameless Green.
2.1. Understanding Testing
A generation ago, a handful of extreme programming (XP) practitioners began writing automated tests using a technique they called "test first development." Their ideas were so influential that automated tests are now the norm, and these tests are often written first, in prelude to writing code.
The practice of writing tests before writing code became known as test-driven development (TDD). In its simplest form, TDD works like this:
-
Write a test.
Because the code does not yet exist, this test fails. Test runners usually display failing tests in red. -
Make it run.
Write the code to make the test pass. Test runners commonly display passing tests in green. -
Make it right.
Each time you return to green, you can refactor any code into a better shape, confident that it remains correct if the tests continue to pass.
In Test-Driven Development by Example, Kent Beck describes this as the Red/Green/Refactor cycle and calls it "the TDD mantra."
The ideas of testing, and of testing first, have won the hearts and minds of programmers. However, a commitment to writing tests doesn’t make this easy. TDD presents a never-ending challenge. You must repeatedly decide which test to write next, how to arrange code so that the test passes, and how much refactoring to do once it does. Each decision requires judgment and has consequences.
If your TDD judgment is not yet fully developed, it’s reasonable to temporarily adopt that of a master. Here’s an excellent guiding principle:
Quick green excuses all sins.
Test-Driven Development by Example
Green means safety. Green indicates that, at least as evidenced by the tests at hand, you understand the problem. Green is the wall at your back that lets you move forward with confidence. Getting to green quickly simplifies all that follows.
This chapter illustrates how to incrementally create tests and then use these tests to drive the development of code. The examples obediently follow the Red/Green/Refactor cycle, but are fairly conservative. Because the initial goal is more about reaching green than writing perfect code, the refactoring step sometimes removes duplication and other times retains it.
The plan is to create tests that thoroughly describe the "99 Bottles" problem, and then to solve the problem with the implementation known as Shameless Green. The Shameless Green solution strives for maximum understandability but is generally unconcerned with changeability. Shameless Green does not assert that changeability isn’t important; it merely recognizes that getting to green quickly is often at odds with writing perfectly changeable code. This chapter concentrates on creating the tests and writing simple code to pass them. Future chapters refactor the resulting code to improve the design.
2.2. Writing the First Test
The first test is often the most difficult to write. At this point, you know the least about whatever it is you intend to do. Your problem is a big, fuzzy, amorphous blob, and it’s challenging to reach in and carve off a single piece. It feels important to choose well, because where you start informs how you’ll proceed, and ultimately determines where you’ll end. The first test can therefore seem fraught with peril.
Despite its apparent import, the choice you make here hardly matters. In the beginning, you have ideas about the problem but actually know very little. Your ideas may turn out to be correct, but it’s just as possible that time will prove them wrong. You can’t figure out what’s right until you write some tests, at which time you may realize that the best course of action is to throw everything away and start over. Therefore, the purpose of some of your tests might very well be to prove that they represent bad ideas. Learning which ideas won’t work is forward progress, however disappointing it may be in the moment.
So, while it is important to consider the problem and to sketch out an overall plan before writing the first test, don’t overthink it. Find a starting place and get going, in faith that as you proceed, the fog will clear.
If you were to sketch out a public Application Programming Interface (API) for "99 Bottles," it might look like this:
-
verse(n) Return the lyrics for the verse number n
-
verses(a, b) Return the lyrics for verses numbered a through b
-
song()Return the lyrics for the entire song
This API allows others to request a single verse, a range of verses, or the entire song.
Now that you have a plan for the API, there are a number of possibilities for the first test. You could write a test for the entire song, for a series of contiguous verses, or for any single verse. Because the easiest way to get started is to tackle something that you thoroughly understand, it makes sense to begin by testing a single verse, and the most logical first verse to test is the first verse to be sung. Here’s that test, written in Jest:
1 describe('Bottles', () => {
2 test('the first verse', () => {
3 const expected =
4 '99 bottles of beer on the wall, ' +
5 '99 bottles of beer.\n' +
6 'Take one down and pass it around, ' +
7 '98 bottles of beer on the wall.\n';
8 expect(new Bottles().verse(99)).toBe(expected);
9 });
10 });The test above is as simple as can be, but notice that writing it required making many decisions. It
contains both a class name (Bottles) and a method name
(verse(n)). This test assumes that the
Bottles class defines a verse method that takes a number as an argument, and it
asserts that invoking that method with an argument of 99 returns the lyrics for the 99th
verse.
This test, like all tests, contains three parts:
-
Setup Create the specific environment required for the test.
-
Do Perform the action to be tested.
-
Verify Confirm the result is as expected.
Lines 3-7 above define the expected result and are thus part of
the setup. Setup continues on line 8, where a new bottle is created via
new Bottles(). Line 8 also
sends verse(99), which is the action, and then verifies the result with
toBe.
Running that test produces this error:
ReferenceError: Bottles is not defined
5 | 'Take one down and pass it around, ' +
6 | '98 bottles of beer on the wall.\n';
> 7 | expect(new Bottles().verse(99)).toBe(expected);
| ^
8 | });
9 | });
10 |TDD tells you to write the simplest code that will pass this test. In this case, your goal is to write
only enough code to change the error message. The above error states that the Bottles class does not yet exist, so the first step is
to define it, as follows:
1 class Bottles {
2 }If you’re new to TDD, this may seem like a ridiculously small step. Because you wrote the test, you can confidently predict that running it a second time will now produce the following error:
TypeError: (intermediate value).verse is not a function
7 | 'Take one down and pass it around, ' +
8 | '98 bottles of beer on the wall.\n';
> 9 | expect(new Bottles().verse(99)).toBe(expected);
| ^
10 | });
11 | });
12 |You can change this error message by adding a verse method.
1 class Bottles {
2 verse() {
3 }
4 }Running the test again produces the following error:
expect(received).toBe(expected) // Object.is equality
Expected: "99 bottles of beer on the wall, 99 bottles of beer.
Take one down and pass it around, 98 bottles of beer on the wall.
"
Received: undefined
7 | 'Take one down and pass it around, ' +
8 | '98 bottles of beer on the wall.\n';
> 9 | expect(new Bottles().verse(99)).toBe(expected);
| ^
10 | });
11 | });
12 |There’s finally sufficient code so that the test fails because the output is not as expected instead of dying because of an exception.
Jest shows the difference between expected and actual output by prefixing the
expected with Expected: and the actual with Received:. Therefore, you
can interpret the above failure as indicating that Jest expected…
-
"99 bottles of beer on the wall, 99 bottles of beer." followed by a newline, followed by
-
"Take one down and pass it around, 98 bottles of beer on the wall." followed by another newline
but instead got undefined.
Pay particular attention to how newlines are represented above. The expected output string contains two
newlines, specified as \n in the test and shown as line
breaks above. The last expected line (which contains only
") represents the empty line that follows the final newline.
Once you reach this point, it’s easy to make the test pass; just copy the expected output into the
verse method:
1 class Bottles {
2 verse() {
3 return (
4 '99 bottles of beer on the wall, ' +
5 '99 bottles of beer.\n' +
6 'Take one down and pass it around, ' +
7 '98 bottles of beer on the wall.\n'
8 );
9 }
10 }Although this code passes the test, it clearly doesn’t solve the entire problem. As a matter of fact, writing a second test will break it. While it may seem pointless to write an obviously temporary and transitional bit of code, this is the essence of TDD.
You as the writer of tests know that the verse method must eventually take the value of its
argument into account, but you as the writer of code must act in ignorance of this fact. When doing TDD,
you toggle between wearing two hats. While in the "writing tests" hat, you keep your eye on the big
picture and work your way forward with the overall plan in mind. When in the "writing code" hat, you
pretend to know nothing other than the requirements specified by the tests at hand. Thus, although each
individual test is correct, until all are written, the code is incomplete.
2.3. Removing Duplication
Now that the first test passes, you must decide what to test next. This next test should do the simplest, most useful thing that proves your existing code to be incorrect. While it may have been difficult to conceive of the first test because the possibilities seem infinite, this next test is often easier because it checks something relative to the first.
Verses 99 through 3 are nearly identical—they differ only in that the number changes within each verse. The test above already checks the high end of this range, and therefore it now makes sense to test the low.
The following test for verse 3 exposes the current verse method to be insufficient:
1 test('another verse', () => {
2 const expected =
3 '3 bottles of beer on the wall, ' +
4 '3 bottles of beer.\n' +
5 'Take one down and pass it around, ' +
6 '2 bottles of beer on the wall.\n';
7 expect(new Bottles().verse(3)).toBe(expected);
8 });TDD requires that you pass tests by writing simple code. However, most programming problems have many
solutions, and it’s not always clear which one is simplest. For example, the following code passes
the current tests by naming the incoming argument and adding a conditional that checks the value of
number and returns the correct string:
1 verse(number) {
2 if (number === 99) {
3 return (
4 '99 bottles of beer on the wall, ' +
5 '99 bottles of beer.\n' +
6 'Take one down and pass it around, ' +
7 '98 bottles of beer on the wall.\n'
8 );
9 } else {
10 return (
11 '3 bottles of beer on the wall, ' +
12 '3 bottles of beer.\n' +
13 'Take one down and pass it around, ' +
14 '2 bottles of beer on the wall.\n'
15 );
16 }
17 }At first glance, this code appears to have achieved the ultimate in simplicity. It can produce only the lyrics for verses 99 and 3, and so does the absolute minimum needed to pass the tests.
But consider that it now contains a conditional where none existed before. This may cause you to recall the discussion on Cyclomatic Complexity in Chapter 1. This conditional adds a new execution path through the code, and additional execution paths increase complexity. This code is simple in the sense that it can’t do much, but it does that one small thing in an overly complex way.
Part of the problem is that although the if statement switches on
number, the true and false branches contain many
things that don’t vary based on number. The
branches do differ in that one says 99/98, and the other 3/2, but they are the same for all of the other
lyrics. This code conflates things that change with things that remain the same, and so forces you to
parse strings with your eyes to figure out how
number matters.
If you were to alter the if statement to return only the things that change, the code would
look like this:
1 verse(number) {
2 let n;
3
4 if (number === 99) {
5 n = 99;
6 } else {
7 n = 3;
8 }
9
10 return (
11 `${n} bottles of beer on the wall, ` +
12 `${n} bottles of beer.\n` +
13 'Take one down and pass it around, ' +
14 `${n - 1} bottles of beer on the wall.\n`
15 );
16 }This code is still very specific to the two existing tests—it can produce the lyrics for verses 99 and 3, and no other. Notice, however, that it now has two parts. The first part (lines 2-8) contains the conditional, and the second (lines 10-15) contains a template that could correctly generate many verses. Lines 2-8 are still specific to the existing tests, but now that you’ve separated the things that change from the things that remain the same, lines 10-15 are generalizable to every verse between 99 and 3.
If you were to continue down the "specific" path, you would progressively add tests for the verses
between 97 and 4, each time altering the if statement to add a condition to check for that
number. Following this strategy would ultimately result in 97 nearly identical tests and 97 nearly
identical verses; each would differ only in the values of the numbers.
The obvious alternative is to instead make the code more general. Because the existing template already
works for every verse between 99 and 3, you could change this code to produce those verses by deleting the
if statement and altering the template to refer to number, as shown here:
1 verse(number) {
2 return (
3 `${number} bottles of beer on the wall, ` +
4 `${number} bottles of beer.\n` +
5 'Take one down and pass it around, ' +
6 `${number-1} bottles of beer on the wall.\n`
7 );
8 }Left to your own devices, your instinct would likely have been to write the code above without bothering with the intermediate steps shown in Listing 2.6: Conditional and Listing 2.7: Sparse Conditional. However, even if you would naturally have started with this more general version, it’s important to understand and be able to articulate the implications of the other implementation.
The difference between the solution that adds a conditional and the solution that adds a variable into a string is that in the first, as the tests get more specific, the code stays equally specific. Every verse has its own personal test and its own individual code; there will never be a time when the code can do anything which is not explicitly tested.
However, in Listing 2.8: Generalized Verse, as the tests get more specific, the code gets more generic. Once the test of verse 3 is written, the code is then generalized to produce lyrics for all verses within the 3-99 range.
Remember that the purpose of this chapter is to quickly get to Shameless Green. With that goal in mind, consider the above solutions and answer this question: Which is simplest?
As previously noted, metrics aren’t everything, but they can certainly be a useful something. In hopes that data will help answer this question, the following chart shows Source Lines Of Code, Cyclomatic Complexity and ABC metrics for the variants, calculated roughly with pencil and paper.
| Solution | SLOC | Cyclomatic Complexity | ABC |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
As you can see, as the examples progress, they get shorter, and the Cyclomatic Complexity score improves. The ABC score, on the other hand, gets worse before it gets better. You must, of course, take metrics with a grain of salt, but here they cast a clear vote for replacing duplication with an abstraction as done in Listing 2.8: Generalized Verse.
The next section examines a nearly identical situation where the choice of what to do about duplication is not nearly so clear-cut.
---Skip to Chapter 8---
8. Developing a Programming Aesthetic
Until now, most changes to the "99 Bottles" code have been the result of formal refactorings. You’ve been an active participant in that you’ve selected code smells to attack and picked recipes to follow, but the resulting code was primarily dictated by those recipes. The process has been both prescriptive and proscriptive; the refactoring recipes tell you what to do while at the same time forbidding you from wandering off to tinker on tangential shiny things.
This chapter lifts its gaze and considers a few problems where the solutions aren’t so clear cut. Sometimes neatly arranged, recipe-driven, fully working code remains unsatisfying because it feels like it isn’t quite good enough. Perhaps it retains a bit of duplication, or has a place where adding another abstraction would make it easier to fulfill an anticipated requirement, or is implemented in a way that makes you fear for its maintainability.
Voluntarily altering working code costs money, and doing so declares that you believe that rearranging this code right now is more important than anything else on the backlog. The opportunity cost of improving existing code is that you can’t simultaneously attend to other urgent things.
If you’re bothered by something in code, you likely have an idea of what you’d prefer. The conundrum posed by these fuzzier situations is not in figuring out what to do, but in deciding whether you’re justified in doing anything at all.
Code smells and refactoring recipes represent the distilled judgement of many deeply experienced OO practitioners. Those folks wrote piles of code, both good and bad, and over time noticed correlations between code arrangements and costs. Close attention to ultimate outcomes led them to develop a sense of what to actively do (or diligently avoid) in present code to preclude future pain. They developed a feeling, an "aesthetic", about the rightness of code, and this aesthetic guided their decisions in times of confusion and uncertainty.
Over time their aesthetic sense of what was pleasing and beneficial got codified into a set of rules, or heuristics. These heuristics became the code smells and refactoring recipes that have been bequeathed to you. The definitions and directions contained therein cover a lot of ground and solve many problems, but do not substitute for developing a programming aesthetic of your own.
The goal of this chapter is to start you down that path.
---Skip to Summary---
8.9. Summary
This chapter pulled the lyrics of the "99 Bottles" song out of Bottles and put them into a
new BottleVerse class. It then injected an instance of BottleVerse back into
Bottles. Extracting BottleVerse reduced the Bottles's
responsibilities, making it easier to understand and maintain. Injecting BottleVerse into
Bottles loosened the coupling between Bottles and the outside world.
Bottles now thinks of itself as being injected with players of the verse template role and
will happily collaborate with any newly arriving object as long as that object responds to
lyrics(number).
The impetus behind extracting BottleVerse was a new requirement to produce songs with
different lyrics, that is, to vary the verse. The refactorings in this chapter satisfied that requirement
by following a fundamental strategy of object-oriented design: extracting the BottleVerse
class isolated the behavior that the new requirement needed to vary.
While continuing to lean on code smells and refactoring recipes, this chapter introduced the idea of a programming aesthetic. A programming aesthetic is the set of internal heuristics that guide your behavior in times of uncertainty. Vague feelings about the rightness of code become part of your aesthetic once you can eloquently and convincingly use actual words to explain your concerns and proposed improvements. A good programming aesthetic focuses attention on improvements that are likely to prove worthwhile.
This chapter suggested five precepts that belong in everyone’s object-oriented programming aesthetic:
-
Put domain behavior on instances.
-
Be averse to allowing instance methods to know the names of constants.
-
Seek to depend on injected abstractions rather than hard-coded concretions.
-
Push object creation to the edges, expecting objects to be created in one place and used in another.
-
Avoid Demeter violations, using the temptation to create them as a spur to search for deeper abstractions.
The practical effect of following these precepts is to loosen the coupling between objects. The code to which you would apply them generally already works so adherence might seem optional, and is certainly not free. Complying with these precepts will frequently increase the amount of code and add levels of indirection, at least in the short term. However, these added costs are overwhelmingly offset by the eventual savings accrued as a result of decoupling.
Any application that survives will change. The only thing of which you can be more confident is that you cannot predict where this change will occur. The certainty of change coupled with the uncertainty of that change’s location means that your best programming strategy is to strive to loosen the coupling of all code everywhere from the moment of initial creation.
Therefore, these precepts don’t attempt to guess the future; rather, they leverage against it. Instead of writing code that speculatively imagines a later need for one specific feature, they tell you to loosen the coupling of all code so that you can easily adapt to whatever future arrives.
Uncertainty about the future is not a license to guess; it’s a directive to decouple. Your future will be brighter if you develop a programming aesthetic that drives you to do so.
9. Reaping the Benefits of Design
The current "99 Bottles" application satisfies all of the known requirements. The code looks very object-oriented, and you can articulate a persuasive justification for every decision that led to its current shape.
But the tests are a bit musty. They’ve gradually transformed from tests that tell a helpful story about the "99 Bottles" song into tests that misrepresent, if not outright lie, about the entire domain. Their only redeeming quality is that at least they fail if the code gets broken.
It’s important to know if something breaks, but tests can do far more. They give you the opportunity to explain the domain to future readers. They expose design problems that make code hard to reuse. Well-designed code is easy to test; when testing is hard, the code’s design needs attention.
Writing tests, even at this late date, will improve the code. As a final exercise, this chapter does just that.
---Skip to Summary---
9.5. Summary
Tests help prevent errors in code, but to characterize them so simply is a disservice; they offer far more. Good OO is built upon small, interchangeable objects that interact via abstractions. The behavior of each individual object is often quite obvious, but the same cannot be said for the operation of the whole. Tests fill this breach.
Object-oriented applications rely on message sending. The key virtue of messages is that they add indirection. Messages allow the sender to ask for an abstraction and be confident that the receiver will use the appropriate concrete implementation to fulfill the request. Senders are responsible for knowing what they want, receivers, for knowing how to do it. Separating intention from implementation in this way allows you to introduce new variations without altering existing code; simply create a new object that responds to the original message with a different implementation.
When designed with the following features, object-oriented code can interact with new and unanticipated variants without having to change:
-
Variants are isolated.
They’re usually isolated in some kind of object, often a new class. -
Variant selection is isolated.
Selection happens in factories, which may be as simple as isolated conditionals that choose a class. -
Message senders and receivers are loosely coupled.
This is commonly accomplished by injecting dependencies. -
Variants are interchangeable.
Message senders treat injected objects as equivalent players of identical roles.
Initially, this reliance on abstractions and indirection increases the complexity of code. What OO promises in return is a reduction in the future cost of change. Highly concrete, tightly coupled code will resist tomorrow’s change. Code that depends on loosely coupled abstractions will encourage it.
Because tests need to execute code, they supply early and direct information about inadequate design, and they provide impetus and inspiration for refinements. When tests are difficult to write, require lots of setup, or can’t tell a satisfying story, something is wrong. Listen. Fixing problems now is not only cheaper than fixing them later, but will improve your code, clarify your tests, and make glad your work.
Afterword
Congratulations, you’ve made it. You are now, if not at the end of all things, at least at the end of this thing. Completing this book is an accomplishment, and you deserve to take a minute to revel in your success before moving on. Regardless of your mindset or experience level before you started, you’re different now that you’re done.
This book has two primary goals. The first relates to process, and the second, perspective.
The first goal is to supply concrete, repeatable techniques that you can employ to improve your own applications. These techniques were illustrated, not just with code, but also by chronicling the rationale behind every decision—there was no hand-waving around awkward corners. The detailed, specific explanations eventually accumulated into a number of general ideas, or canons, about how to write code.
Strive for simplicity. Don’t abstract too soon. Focus on smells. Concentrate on difference. Take small steps. Follow the Flocking Rules. Refactor under green. Fix the easy problems first. Work horizontally. Seek stable landing points. Be disciplined. Don’t chase the shiny thing.
In addition, deal with new requirements by first refactoring existing code to be open to them, and then writing new code to meet them. Achieving openness is usually the more challenging task, but can be sought in absolute safety if you have tests that act as a wall at your back.
You may need better tests. If so, writing them will save you money.
The canons are practical rules that guide the programming process. Adhering to them will lower your stress, speed up your work, and improve your code. If you commit to nothing more than to follow them, your reading time will have been well spent.
However, this book is not just about process. It has a second, more abstract, goal—it aspires to infect you with a certain perspective about object-oriented programming. This book wants you to fall in love with polymorphism.
When you write conditionals that supply behavior, and put those conditionals in classes whose names other classes know, your code depends upon concretions, and will break with every change.
However, when you disperse behavior into polymorphic objects, you can use factories to isolate both the names of the classes and the conditionals that choose them. Factories instantiate role-playing objects, which you can then inject as dependencies. When you inject smart dependencies, and trust them to behave correctly, your code depends upon abstract roles rather than on concrete classes. This loosens the coupling between objects and makes code open to change.
Trust is necessary, but the path to reaching it is circular. Acting in trust requires faith, and faith can only be earned by trustworthiness. Your objects must be trustworthy, and your code must trust your objects. Failing at either obligation dooms you to conditionals.
The secret to programming happiness is to combine the canons with the infection, building applications from polymorphic, trustworthy objects, and changing them one step at a time.
That’s officially the end, but before you go, one last request.
Hold high standards, but judge yourself gently. Perfection is just not that likely. Most times the requirements you’re given aren’t quite right, or are incompletely conveyed, or misunderstood, or about to change, ad nauseam. Circumstances conspire to make it hard to get everything exactly right, despite your best efforts.
Think of your code as a message in a bottle, written in haste for future readers. They’ll always know more than you know right now. Your job is not to be perfect, but to write a generous and sympathetic story. Tell them a story they can understand, and they’ll cherish you forever.
Thanks for reading, and we hope that you’ve enjoyed the book.